Java程序员学习Go指南
从事java编码也有三年多了,写的Java代码也很多。Go语言,我是无意间接触到的。在去年12月份左右的时候比特币大涨到1w刀,就想着研究下比特币,而同时有听说Go语言在区块链中非常火爆。就抱着学着看看的心情了解了Go,不知不觉喜欢上Go语言的简洁和优雅了。
Go语言是谷歌推出的一种全新的编程语言,可以在不损失应用程序性能的情况下降低代码的复杂性。Go语言的高并发支持,语法的简洁性,指针的自动垃圾回收,可以让开发人员将精力放在业务处理上。Go语言能够将开发人员带入更生层次的去了解底层操作系统,而不仅局限于语言本身。Go语言的”Less is more”,需要在编码过程中去体会这种设计哲学!
以数据交换为例子,Go语言实现:array[i] , array[j] = array[j] , array[i] // Go
用Java实现:1
2
3int temp = array[i];
array[i] = array[j];
array[j] = temp;
语法
在语法上Go相对Java有着很多开发人员非常喜欢的特性。可以说这些特性,设计的非常人性化。大大简化了开发人员的工作。语法上从以下四点介绍Java和Go区别
变量,赋值操作
在变量命名规则上Java和Go基本相同,都是大小写字母数字,下划线,不能以数字开头。但在Go中以大写字母开头的变量、方法、函数、结构体都表示public(对所有类可见)类型,小写表示private(本类可见)类型(这里不讨论下划线开头)。而Java中用publicprivate关键字明确表示,没有明确表示的为default(包可见)类型,有比较严格的访问级别。Go语言特意淡化了此点,可以节省很多代码。但也为初学者留下了一些小坑,比如JSON序列化时,属性字段必须大写才能序列化。
例如:(Go语言以换行符表示一行代码结束,Java以;表示结束,此法对Go依然适用)1
2
3
4
5
6
7type Response struct {
Message string `json:"message"`//将Message字段序列化成JSON中的message
userName string `json:"userName"`//首字母小写,无法被序列化
}
```
在变量声明赋值上,`Go`语言采用现代化“脚本语言”声明方式。`Go`支持类型自动推断,故在声明变量时可以将变量类型省略。以下一组代码说明变量`a` `b` `c` `d`的多种声明赋值方式,当多个变量赋值时推荐使用最后一种方式,代码量最少。相对于`Java`一行代码只能声明一个变量,要便捷很多。
函数外部申明必须使用`var`,不要采用`:=`。var a int
a = 10
var b int = 10
var c = 10
d := 10
var a, b, c, d = 10
a, b, c, d := 10
a, b, c, d := 10, 10, 11, 121
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
272. 数据类型
`Go`语言中的数据类型与`Java`差距比较大,`Go`常用基本数据类型继承了`C/C++`语言特点。
`Java`中有包装类型,包装类型为对象,`Go`没有此功能。`Go`中还包含一些其他的数据类型简写: `byte` => `uint8`;`int` => `uint`;`uint` => `uint32`或`uint64`;`rune` => `int32`;`uintptr`表示无符号整型,用于存放一个指针。
下面表格具体表示了`Go`和`Java`数据类型对比:
| Go | Java |值范围 | 说明 |
| -------- | :----- |:--- | :---- |
|bool | boolean |true,false | - |
|uint8 | - |0 ~ 2^7-1 |无符号8位整型 |
|uint16 | - |0 ~ 2^15-1 |无符号16位为整型 |
|uint32 | - |0 ~ 2^31-1 |无符号32位整型 |
|uint64 | - |0 ~ 2^64-1 |无符号64为整型 |
|int8 | byte |-2^7 ~ 2^7-1 |有符号8位整型 |
|int16 | short |-2^15 ~ 2^15-1 |有符号16位整型 |
|int32 | int |-2^31 ~ 2^31-1 |有符号32为整型 |
|int64 | long |-2^63 ~ 2^63-1 |有符号32为整型 |
|float32 | float |IEE754 |32位浮点型 |
|float64 | double |IEE754 |64位浮点型 |
|complex64 | - | |32位实数和虚数 |
|complex128 | - | |64位实数和虚数 |
`Go`的数据类型比`Java`更加丰富,但使用起来上两者相差不多。`Go`中没有包装类型,大大减少`Java`中思考使用包装类型还是简单类型的时间。`Go`中也引入了无符号,有符号数据类型的选择。
在处理中文字符上,`Go`和`Java`一样方便。
3. 指针,`slice`,`map`
- **指针**
`Go`语言仍采用了`C/C++`中的指针,相对于`Java`稍显复杂。但由于`Go`中能够自动垃圾回收,只需要学会灵活使用指针就能够大幅减少内存操作时间,简化代码。可以说Go语言指针是`C/C++`和`Java`的中合。能够享受指针的便捷,同时又省去手动释放指针的麻烦。
指针变量可以指向任何一个值所在的内存地址。`Go`中使用`*`来声明一个指针,同时也是取指针值操作符。`&`用来取内存地址,16进制,例如`0xc420014608`,不同的机器,不同的环境内存地址都会不同。var p *int//声明一个指针 a:=10 p=&a //指针赋值 fmt.Println(p) //打印指针所指向内存地址 0xc420014608 fmt.Println(&a) //a与p所指向内存中同一地址 0xc420014608 fmt.Println(&p) //取变量p地址,会变, 0xc42000e048 fmt.Println(*p) //打印指针内容, 10var a [4]int // 数组 a = [4]int{1, 2, 3, 4}// 数组赋值 b := a[1:3] //slice,数组a的引用,从a数组下标1到下标2 b[1] = 5 //a={1,2,5,4}, b={2,5}1
2
3
4- **`slice`**
`slice`和`Java`中的`List`很像,都是能够自动扩容的数组集合。`Go`中`List`实现了栈和队列的功能,和`Java List`差距比较大。在结构上`Go slice`为动态素组,可以自动根据当前元素和声明的容量进行扩容。使用起来非常方便,但可能会带来性能的消耗,频繁的扩容将使代码运行速率下降。
`slice`有两个额外的属性:`len`(长度),`capacity`(容量), `var c = make([]int, capacity)`
同时需要注意由数组创建的`slice`为数组引用,改变`slice`的值会导致原数组也会发生变化。这种现象在`Go`中非常常见,使用时要格外注意。List<Integer> a = new ArrayList<>(); a.add(1); a.add(2); List<Integer> b = a; b.add(5);1
而在`Java`中其实也是存在这种现象的,不过Java中“一切皆是对象”的原则,我们在创建一个新的变量或者对象时,都是使用new操作,然后再赋值,所以这种对象引用的该变导致原对象也被改变的情况比较少。变量作为参数时,这种情况发生较多,以下Java代码也时有发生:
copy(b, []int{7,3,8}) // b={7,3},由于b的长度只有2,copy只会复制前两位1
`slice`有两个非常重要的函数`copy()`、`append()`。`append`函数用于给`slice`追加元素,当slice容量不够时会自动扩容,例如`b = append(b, 3)`;`copy`函数用于将一个数组拷贝到另一个数组,不会自动扩容,例如:
var m map[int]string // 声明 m[1]="1" // 赋值 fmt.Println(m[1]) // 取值1
2
3- **`map`**
`map`和`Java`中的`HashMap`就设计思想有很多相似的地方,都是非线程安全的数据结构。`Java`中`HashMap`底层采用数组(`bucket`)+链表+红黑树(红黑树为`JDK1.8`新增部分)的数据结构。都是考虑到`Map`的使用场景,牺牲线程安全提升访问效率的实现方式。并发情况下使用`ConcurrentHashMap`。
`Go map`使用方式相比`Java`更为简单,任何数据类型都可以作为`key`(`Java`中`key`必须为对象,基本数据类型的封装类型才能作为key),例如:type ConcurrentHashMap struct { lock *sync.RWMutex //Read and write Lock cm map[interface{}]interface{} } func (m *ConcurrentHashMap) Get(k interface{}) interface{} { m.lock.RLock() //Read Lock defer m.lock.RUnlock() if val, ok := m.cm[k]; ok { return val } return nil } func (m *ConcurrentHashMap) Set(k interface{}, v interface{}) bool { m.lock.Lock() // Write Lock defer m.lock.Unlock() if val, ok := m.cm[k]; !ok { m.cm[k] = v } else if val != v { m.cm[k] = v } else { return false } return true }1
如何用Go实现一个线程安全的map?最直接的方式就是在map读写的时候加上读写锁...
1
2
3
4
5
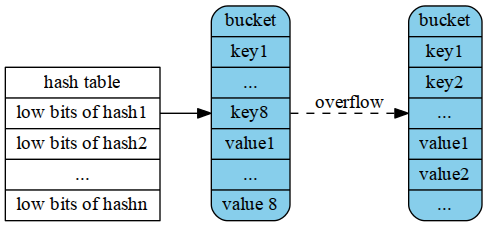
6`Go map`是`hash`结构的,意味着平均访问时间是O(1)的。同传统的`hashmap`一样,由一个个`bucket`组成,`bucket`内部又由一个指针数组组成。按`key`的类型采用相应的hash算法得到`key`的`hash`值。将`hash`值的低位当作Hmap结构体中buckets数组的index,找到key所在的bucket。将hash的高8位存储在了`bucket`的`tophash`中。注意,这里高8位不是用来当作`key/valu`e在`bucket`内部的`offset`的,而是作为一个主键,在查找时对`tophash`数组的每一项进行顺序匹配的。先比较`hash`值高位与`bucket`的`tophash[i]`是否相等,如果相等则再比较`bucket`的第`i`个的`key`与所给的`key`是否相等。如果相等,则返回其对应的`value`,反之,在`overflow buckets`中按照上述方法继续寻找。
数组,`slice`,`map`的遍历都可直接采用`range`关键字,`foreach`的形式遍历,也可采用`for`循环方式遍历。`foreach`遍历和`Java`相同,都**不宜**在遍历过程中改变原值。
4. 方法函数
对于习惯了Java的开发人员来说,总是会将方法和函数当成一个概念,但在Go中这两个确有一些不同之处。但形式差不多,功能相同。
- **函数**,由关键字`func`定义,完成特定功能,可以有多个返回值。例如:`func Add(a int, b int) int { ... }`。形式上和Java有一定差距,功能作用和Java一样。不过Go中能够有多个返回值,这极大的简化了实际功能的完成。一下几个例子说明方法的声明:func Add(a int, b int) int { … }
func Sub(a int, b int) (result int) { … }// result 为返回对象,可在方法体中对result直接赋值
func Multi(a int, b int) (int, string) { … } //多个返回值必须是用括号
func Divide(a int, b int) (result int, s tring) { … }//如果多个返回值中其中一个有返回值变量,其他的也要有返回值变量1
2
3
4- **方法**,函数和方法的定义相差不大。函数一般都是继承某个接口而来,相当于Java中某个类中定义的方法。一个方法就是一个包含了接受者的函数,接受者可以是命名类型或者结构体类型的一个值或者是一个指针。所有给定类型的方法属于该类型的方法集。例如:
`func (user *User) getUserName() string { ... }`示例中的`User`为一个结构体,`getUserName`为结构体的一个方法。
5. 面向对象
Go中面向对象要简单很多,去除了Java,C/C++中复杂的继承关系,保留了接口`interface`和`struct`。`interface`中包含的是方法,`struct`中只能定义属性。`strcut`能够实现`interface`中的方法(函数)。两者相结合使用实现面向对象的思想,相比Java和C/C++简洁了不少,概念也减少了很多。面向对象的思想还在,仍存在对象关联(父子类)关系。type People interface { getUserName() string } type User struct { Name string } func (user *User) getUserName() string { return user.Name } func main() { var p People p = &User{Name: "zhangshan"} //使用User初始化p,p为接口People的实现,只包含方法getUserName() fmt.Print(p.getUserName()) // print "zhangshan" }1
2
3
4
5在`Go`代码中我们要防止接口的滥用,相比`Java`中让人头疼的继承和接口实现,`Go`要相对简单,但我们在使用`interface`时需要考虑是否必要。
## 错误处理
`Go`语言中的错误处理相比`Java`中的`try catch`要相对简单一点,但从另一方面Go中的`Errors are values`却又麻烦很多!习惯了`Java`中的`try`抛出异常,`catch`中处理异常的开发人员来说,可能对于`Go`中的`error`和`panic`处理方式会有点不能适应。
在`Java`中我们通常处理异常(错误)的方式为:将一段可能出错的业务代码使用`try catch`包裹。`try`中进行正常业务逻辑,在`catch`模块对业务逻辑进行补偿操作,事务回滚等,在`finally`模块对资源进行释放。看起来是一段相对严谨的处理逻辑,大多数开发人员处理到这就结束了。但这其中却包含很多不确定性,请看如下代码:
try{
A.close();
}catch(Exception e){
try{
B.close();
}catch(Exception e){
B.close();
}finally{
B.close();
}
}finally{
try{
C.close();
}catch(Exception e){
C.close();
}finally{
C.close();
}
}1
2对于不确定的值,开发人员都会尝试去捕捉,并做出处理,但上述冗长的代码,感觉非常糟糕,最终的情况可能是ABC三个链接都没法正常关闭。`Java`中`try catch`给我们代码方便的同时,却留下很大的“操作空间”,这可能就陷入了一个死胡同。偷懒的开发人员可能会直接放弃处理,而且大多数开发人员都会如此。因为这实在是太冗长了。在实际开发过程中,catch中往往只做了打印异常的功能,很多开发人员补偿都不会做!
而`Go`就将这种情况摆在开发人员的面前(`Java`中开发人员能够睁一只眼闭一只眼),你无法忽视这个问题。`Go`的`error`设计是,错误也是一种合法的值——`“Errors are values”`
err := Sub()
if err != nil { //与常规处理思路相反,优先处理错误
fmt.Print(err)
return err
}
…//正常业务逻辑1
2
3
4
5
6
7
8
9
10
11
12
13`Go`中的异常`panic`会导致整个`Go`程序crash(进一步说明`Go`中的异常必须处理,不可忽略),防止异常导致整个程序崩溃,我们要使用`recover()`来进行恢复。
同时引入关键字`defer`来延迟执行defer后面的函数,非常适合用来处理异常和错误。多条defer函数的处理顺序和声明顺序相反。Go中有很多正确处理错误的实践方式,需要在实际编码过程中体会。
## 并发
Go的并发模型设计来自CSP模型。Golang借用CSP模型的一些概念为之实现并发进行理论支持,其实从实际上出发,go语言并没有完全实现了CSP模型的所有理论。仅仅是借用了process和channel这两个概念。相对于Java的并发设计,使用起来要方便很多,因此Go可以轻易的起成千上万个协程(Goroutine)。(这里并不会讲述Go调度器模型)
Goroutine是实际并发执行的实体,它底层是使用协程(coroutine)实现并发。coroutine是一种运行在用户态的用户线程,类似于greenthread,go底层选择使用coroutine的出发点是因为,它具有以下特点:
- 用户空间 避免了内核态和用户态的切换导致的成本
- 可以由语言和框架层进行调度
- 更小的栈空间允许创建大量的实例
goroutine是在golang层面提供了调度器,并且对网络IO库进行了封装,屏蔽了复杂的细节,对外提供统一的语法关键字支持,简化了并发程序编写的成本。Go中并发编程示例:
1. 使用`channel`控制并发,`channel`又分为带缓冲`buffer`和不带缓冲`buffer`。不带缓冲的channel不能在同一个gorutine读写,否者发生死锁。带缓冲的channel可以。
func main() {
ch := make(chan int) // 声明一个不带缓冲的channel,ch := make(chan int,2) 带缓冲channel,缓冲为2
go func() { // go关键字表示启动一个协程goroutine
ch <- 1 // channel <- 表示向channel中写数据
}()
fmt.Println(<-ch) // i:=<- channle 表示读取channel中的数据到变量i
}
1
2. 使用`sync.WaitGroup`控制并发
fun main(){
var wg sync.WaitGroup
var urls = []string{"http://www.golang.org/", "http://www.google.com/"}
for _, url := range urls {
wg.Add(1) //每有一个goroutinie,wg+1
go func(url string) {
defer wg.Done() // 函数最后将该协程goroutine标记为完成
http.Get(url)
}(url)
}
wg.Wait() // 等待所有的goroutine完成后再执行下面的代码
}
```
- 使用
context实现并发控制。context主要是用来处理goroutine中又开启其他gourine,达到跟踪goroutine的解决方案。主要是用来处理多个goroutine之间共享数据,及多个goroutine的管理。
垃圾回收
Go语言有指针,也有自动垃圾回收。这一点上与Java一致,都采用了标记清除算法,不过Go中还有另外两种垃圾回收算法:位图标记和内存布局,精确的垃圾回收。
讨论垃圾回收,就需要知道为什么要有垃圾回收,那就需要先了解系统是如何分配内存。操作系统中有一个内存池。首先,它会向操作系统申请大块内存,自己管理这部分内存。然后,它是一个池子,当上层释放内存时它不实际归还给操作系统,而是放回池子重复利用。这样反复的过程中,内存管理中必然会出现内存碎片问题,当代码中需要申请一个较大的对象时,原用的碎片空间已经不够使用,这就出现了垃圾回收。
垃圾回收有着非常长的历史,第一批垃圾回收算法是为单核机器和小内存程序而设计的。那个时候,CPU和内存价格昂贵,而且用户没有太多的要求,即使有明显的停顿也没有关系。这个时期的算法设计更注重最小化回收器对CPU和堆内存的开销。也就是说,除非内存不足,否则GC什么事也不做。而当内存不足时,程序会被暂停,堆空间会被标记并清除,部分内存会被尽快释放出来。
分代理论假说,大部分的内存对象“朝生夕死”,它们在分配到内存不久之后就被作为垃圾回收。这就是分代理论假说的基础,它是整个软件产品线 领域最贴合实际的发现。数十年来,在软件行业,这个现象在各种编程语言上表现出惊人的一致性,不管是函数式编程语言、命令式编程语言、没有值类型的编程语言,还是有值类型的编程语言。现代垃圾回收器基本上都是基于分代算法。分代回收器可以加入其它各种特性,一个现代回收器将会集并发、并行、压缩和分代于一身。
例如Java中JVM的GC分为“年轻代”和“老年代”,“年轻代”的对象大多“朝生夕死”,能够存活下来的对象会放到老年代中。是典型的分代回收器。
下面简单分析集中垃圾回收算法:
标记清除算法
我们都知道标记清除算法会“stop the world”。内存单元并不会在变成垃圾立刻回收,而是保持不可达状态,直到到达某个阈值或者固定时间长度。这个时候系统会挂起用户程序,也就是 STW,转而执行垃圾回收程序。
该算法中有一个标记初始的root区域,以及一个受控堆区。root区域主要是程序运行到当前时刻的栈和全局数据区域。在受控堆区中,很多数据是程序以后不需要用到的,这类数据就可以被当作垃圾回收了。判断一个对象是否为垃圾,就是看从root区域的对象是否有直接或间接的引用到这个对象。如果没有任何对象引用到它,则说明它没有被使用,因此可以安全地当作垃圾回收掉。
标记清扫算法分为两阶段:标记阶段和清扫阶段。标记阶段(Go采用的是三色标记法),从root区域出发,扫描所有root区域的对象直接或间接引用到的对象,将这些对上全部加上标记。在回收阶段,扫描整个堆区,对所有无标记的对象进行回收。)more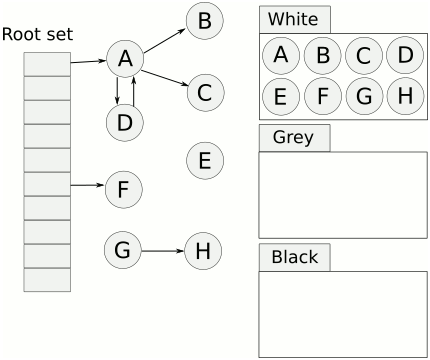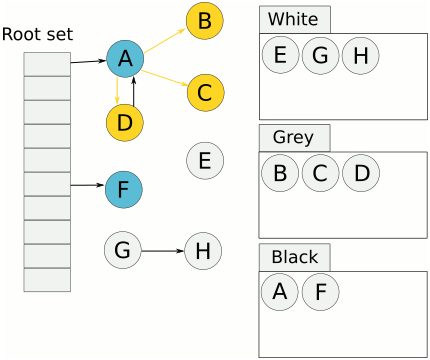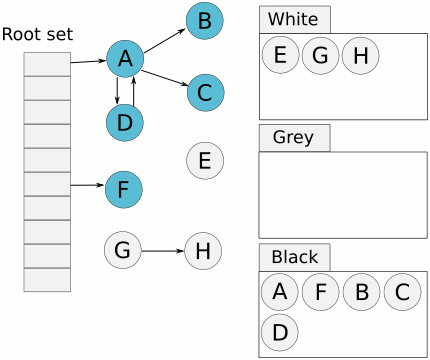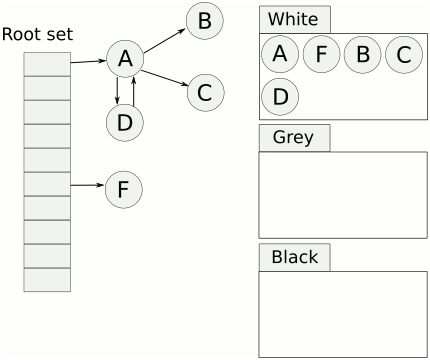
位图标记和内存布局
既然垃圾回收算法要求给对象加上垃圾回收的标记,显然是需要有标记位的。一般的做法会将对象结构体中加上一个标记域,一些优化的做法会利用对象指针的低位进行标记,这都只是些奇技淫巧罢了。Go没有这么做,它的对象和C的结构体对象完全一致,使用的是非侵入式的标记位.精确垃圾回收
通过定位对象的类型信息,得到该类型中的垃圾回收的指令码,通过一个状态机解释这段指令码来执行特定类型的垃圾回收工作。对于堆中任意地址的对象,找到它的类型信息过程为,先通过它在的内存页找到它所属的MSpan,然后通过MSpan中的类型信息找到它的类型信息。more
微服务架构
Go作为一个现代化后端程序语言,搭建微服务架构当然也是没有任何问题的。Go通常采用Go-Kit作微服务框架,Java通常采用Spring Cloud做微服务架构。
微服务的架构主要关键包含以下几点:
服务拆分
服务拆分粒度主要看具体业务需求,不易太宽泛,也最好不要太细,不然就会产生几十个微服务,维护成本较大。服务治理(服务注册发现)
服务注册发现又分为两种:- 客户端发现模式
当使用客户端发现模式时,客户端负责决定相应服务实例的网络位置,并且对请求实现负载均衡。客户端从一个服务注册服务中查询,其中是所有可用服务实例的库。客户端使用负载均衡算法从多个服务实例中选择出一个,然后发出请求。服务实例的网络位置是在启动时注册到服务注册表中,并且在服务终止时从注册表中删除。服务实例注册信息一般是使用心跳机制来定期刷新的。Netflix Eureka是一个服务注册表,为服务实例注册管理和查询可用实例提供了REST API接口。Netflix Ribbon是一种IPC客户端,与Eureka合同工作实现对请求的负载均衡。 服务端发现模式
客户端通过负载均衡器向某个服务提出请求,负载均衡器向服务注册表发出请求,将每个请求转发往可用的服务实例。跟客户端发现一样,服务实例在服务注册表中注册或者注销。Java微服务实践中通常使用
Spring Cloud框架,使用Eureka作为微服务的服务注册表,spring封装了Eureka,让Eureka即作服务转发又作服务注册表。
Go中可以使用Consul(一个用于发现和配置的服务。提供了一个API允许客户端注册和发现服务。Consul可以用于健康检查来判断服务可用性),etcd(一个高可用,分布式的,一致性的,键值表,用于共享配置和服务发现。两个著名案例包括Kubernetes和Cloud Foundry)
- 客户端发现模式
远程调用RPC
在RPC方面Java和Go均可采用GRPC、Apache thrift或者直接采用Restful风格的Http请求。Java也可采用dubbo封装的RPC方式高可用,负载均衡
服务治理能够在服务与服务之间时间负载均衡。HTTP反向代理和负载据衡器(例如NGINX)可以用于服务发现负载均衡器。服务注册表可以将路由信息推送到NGINX,激活一个实时配置更新;例如,可以使用Consul Template。NGINX Plus支持额外的动态重新配置机制,可以使用DNS,将服务实例信息从注册表中拉下来,并且提供远程配置的API。网关,路由追踪
理论上说,一个客户端可以直接给多个微服务中的任何一个发起请求。每一个微服务都会有一个对外服务端(https://serviceName.api.company.name)。这个URL可能会映射到微服务的负载均衡上,它再转发请求到具体节点上。
通常来说,一个更好的解决办法是采用API Gateway的方式。API Gateway是一个服务器,也可以说是进入系统的唯一节点。这跟面向对象设计模式中的Facade模式很像。API Gateway封装内部系统的架构,并且提供API给各个客户端。它还可能有其他功能,如授权、监控、负载均衡、缓存、请求分片和管理、静态响应处理等。Java中通常使用zuul来搭建服务器网关。
最后给大家推荐我的几个Repo
- blockchain,简易区块链demo
- crawler,开车爬图专用(好用的repo没人star)
- go-kit-demo,Go微服务demo